
At 3 AM Beijing time, OpenAI launched ChatGPT Images 2.0.

- Live link: https://openai.com/zh-Hans-CN/live/
ChatGPT Images 2.0 is described as the next evolution: a state-of-the-art model capable of handling complex visual tasks and generating precise, usable visual content.
OpenAI’s official blog provides two versions (image mode and classic mode), with the image mode content entirely generated by the model!
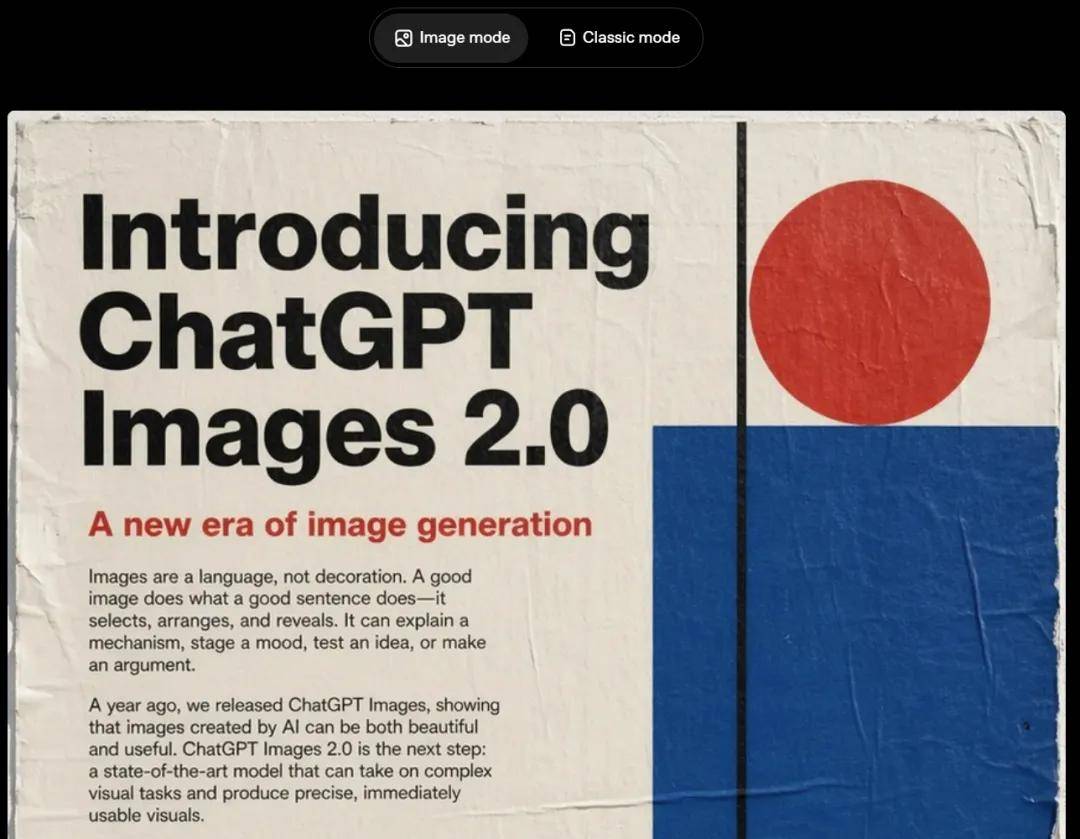
- Blog address: https://openai.com/index/introducing-chatgpt-images-2-0/
In the blog, OpenAI states: “Images are a language, not decoration. Good images, like good sentences, involve selection, organization, and presentation. They can explain mechanisms, create atmospheres, validate ideas, or build arguments.”
The ChatGPT Images 2.0 model has achieved a qualitative leap in following instructions, accurately placing and relating objects, and rendering high-density text while supporting various aspect ratios. Its capabilities in composition and visual aesthetics make the outputs appear less like “AI-generated” and more like “intentionally designed”.
It also performs accurately in multilingual environments, utilizing extended visual and world knowledge to fill in details, resulting in smarter images with fewer prompts.
To tackle the most complex tasks, Images 2.0 introduces “thinking capabilities” for the first time. When selecting the thinking or pro model in ChatGPT, Images 2.0 can access real-time information, generate multiple different images from one prompt, and review its own outputs. With “thinking,” the model can undertake more work between ideas and images, especially when accuracy, timeliness, consistency, and visual unity are crucial.
Combining OpenAI’s reasoning model intelligence with a deep understanding of the visual world, this model elevates image generation from “rendering” to “strategic design,” evolving from a tool into a visual system that helps people transform ideas into understandable, shareable, teachable, and buildable outcomes.
This capability is now available to all ChatGPT, Codex, and API users starting today.
Higher Precision and Control
Images 2.0 brings unprecedented specificity and fidelity to image creation. It can conceive more complex images and effectively realize them, strictly following instructions, retaining key details, and rendering fine elements that previous models struggled with: small text, icons, UI elements, high-density compositions, and subtle stylistic constraints. The API supports up to 2K resolution. The results are no longer “close enough” but are “ready to use”.
Notice that the screenshot below is actually generated by Images 2.0!
Stronger Multilingual Capabilities
Previous image generation models performed more reliably in English and Latin alphabet languages, but showed lower accuracy in other languages, especially with complex or dense text.
Images 2.0 breaks this limitation, significantly enhancing multilingual understanding, particularly in rendering text in Japanese, Korean, Chinese, Hindi, and Bengali. It can not only correctly generate non-English text but also ensure natural and fluent language expression.

This means not just translating labels, but making language itself a part of the design, achieving unity between visuals and language in posters, explanatory graphics, diagrams, and comics. This gives the model stronger global applicability, allowing users to create visual content in the languages they actually use.
During the live broadcast, a member of the OpenAI image research team, Chen Boyuan, demonstrated a case where he prompted: “Make an artistic marketing poster for a fictional OpenAI bakery. The poster should be in Japanese language.”
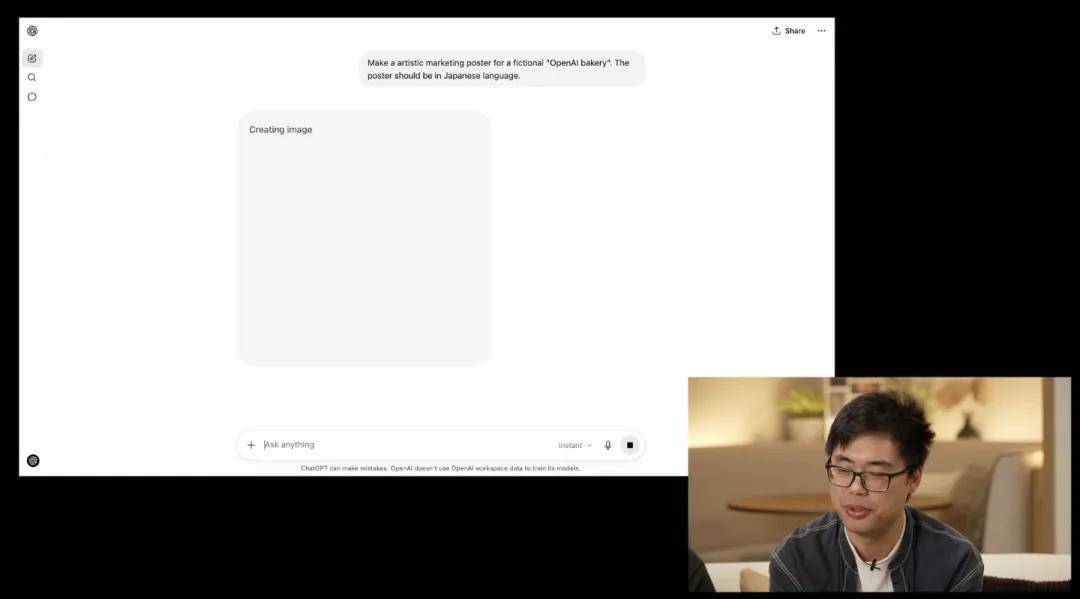
The resulting poster fully met the prompt, achieving precision in details.

“It excels at following very detailed instructions, so if you have very specific brand language or design aesthetics — all those things that are crucial for creative work — you can use ChatGPT to create and refine your ideas to get the results you want,” said Chen Boyuan.
More Mature Style Expression and Realism
Images 2.0 significantly improves fidelity across various visual styles. It excels at capturing key features of photographs, including small imperfections that enhance realism, while also consistently presenting cinematic visuals, pixel art, comics, and various visual languages, with greater consistency in texture, lighting, composition, and detail.

Thus, the model’s outputs are closer to the specified style rather than mere approximations. This is particularly valuable for game prototype design, storyboarding, marketing creativity, and asset creation for specific media or types.
Flexible Aspect Ratios
The new model offers greater flexibility in output formats, supporting various aspect ratios from 3:1 to 1:3, directly adaptable for banners, presentations, posters, mobile interfaces, bookmarks, and social media graphics. You can specify the aspect ratio in the prompt or regenerate existing images to new dimensions using preset options.
Below are examples of two unconventional aspect ratios:

Stronger Real-World Understanding
Images 2.0 introduces knowledge up to December 2025, further enhancing relevance and contextual accuracy in generated results. This is particularly critical for explanatory graphics, educational visuals, and visual summaries, where correctness and clarity are as important as aesthetics.
Its intelligent capabilities also manifest in end-to-end task handling: integrating information, writing content, and formatting with clear structure, reasonable white space, and good visual flow.

Visual Thinking Partner
When the thinking model is enabled in ChatGPT, the system performs deeper understanding and execution in the background. It can retrieve information online, transform uploaded materials into clear visual explanations, and reason about the image structure before generation.
In this mode, Images 2.0 acts more like a visual thinking partner, helping you advance initial concepts into complete products, significantly reducing workload.

It also supports generating multiple different images at once, a first in ChatGPT image generation. This makes workflows like multi-page comics, entire house design plans, series posters, or multilingual, multi-size social media materials efficient and feasible.
You no longer need to generate each image separately and manually stitch them together; a single request can yield up to eight outputs that maintain consistency in characters and elements, with continuity.
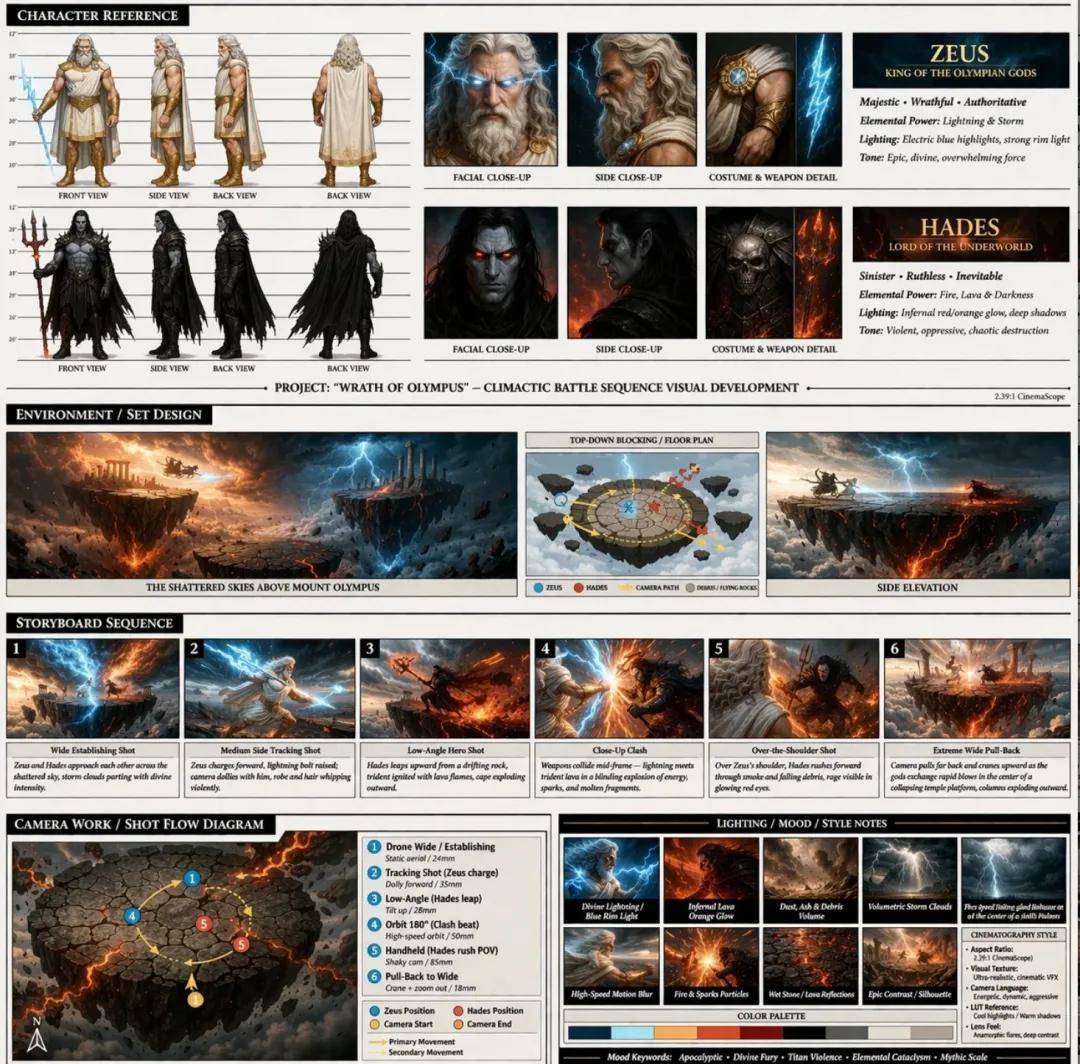
Using Image Generation in Codex
Image capabilities have been integrated into Codex, allowing visual creation, iteration, and delivery to be completed within the same workspace, expanding its applications in design, marketing, product, sales, and learning.
For example, you can quickly generate various UI directions and prototypes, compare options, and directly convert the best designs into products or web experiences without leaving Codex. Available through ChatGPT subscription without needing an additional API key.
Embedding Image Capabilities into Products via API
Developers and businesses can integrate these capabilities into their products through the gpt-image-2 API, adding high-quality image generation and editing capabilities into existing workflows.
With stronger text rendering, multilingual generation, instruction-following capabilities, and more output formats and aspect ratio support, the API is easier to build image workflows in real business scenarios, such as localized advertising, infographics, explanatory graphics, educational content, design tools, creative platforms, and web generation products.
Limitations
OpenAI also mentioned the limitations of the model in the blog: Although Images 2.0 is an important advancement, it is still not perfect. For tasks requiring complete physical world modeling (such as origami tutorials, Rubik’s Cube structures, etc.) and precise details of hidden surfaces, slanted surfaces, or reverse surfaces, the model may still perform inadequately.
Extremely high-density or repetitive details (like fine sand) may also pose challenges. For labels and diagrams involving precise arrows or component annotations, manual proofreading is still recommended.
These are all important directions for future improvements.
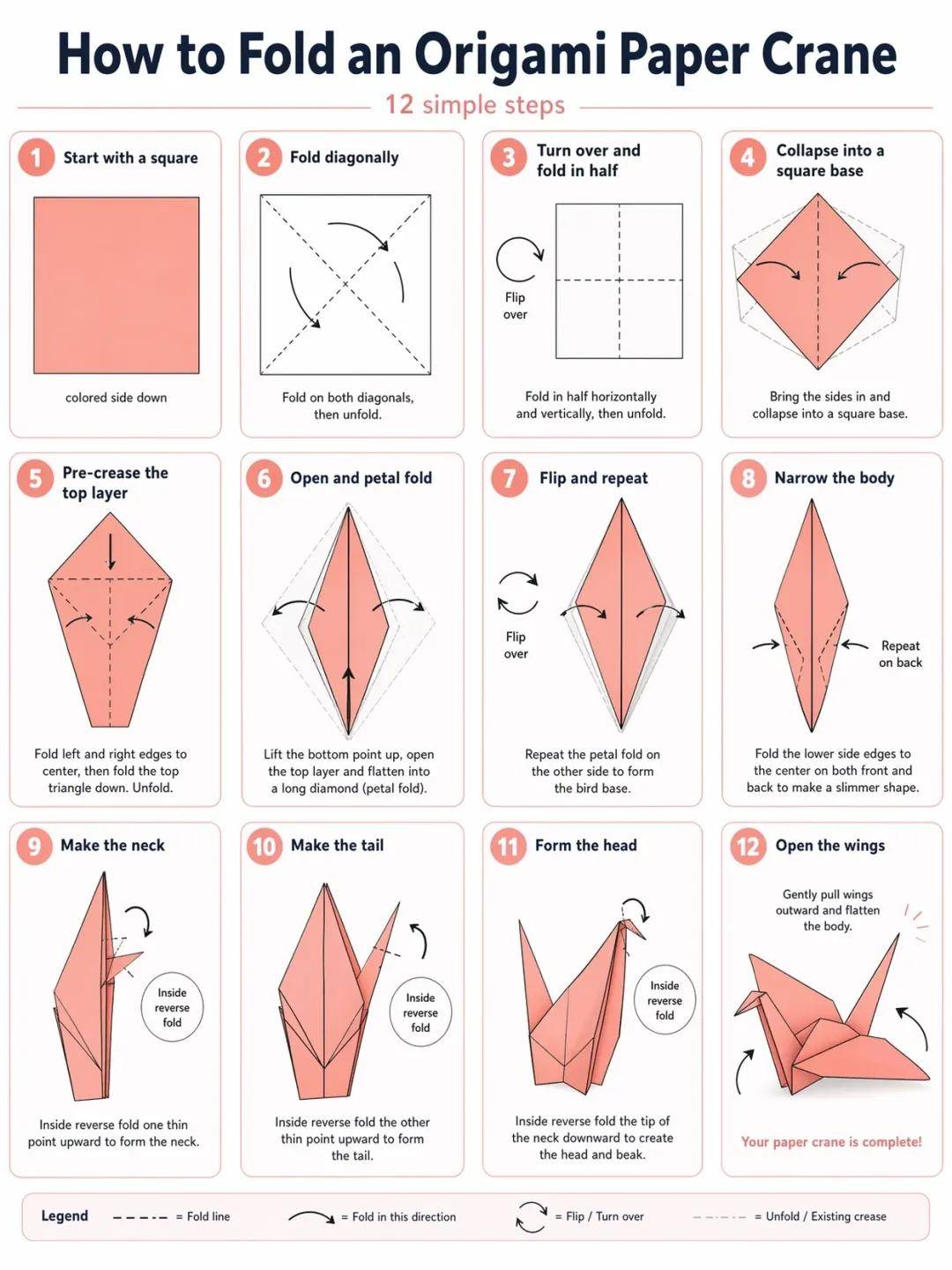
In the API, outputs above 2K are still in testing phases and may exhibit instability.
Pricing and Availability
ChatGPT Images 2.0 is now available to all ChatGPT and Codex users. Advanced outputs with “thinking” capabilities are available to ChatGPT Plus, Pro, and Business users.
gpt-image-2 model is available in the API, with pricing varying based on image quality and resolution.

OpenAI has also launched a plethora of examples on its official website, which interested readers can check out.
We also conducted some simple tests, such as generating a page from the Chinese Gaokao math exam, which looked decent:

In practice, we can see that generating an image with ChatGPT Images 2.0 typically goes through several steps: creation → drafting → generating a first draft → building the scene → refining details → finishing → final polishing → final adjustments.
Next, we continued with the prompt, “Generate a traditional Chinese cursive calligraphy work of ‘Toasting Wine’, aspect ratio 3:1, with the content being the full text of Li Bai’s ‘Toasting Wine’. The signature is ChatGPT Images 2.0”:

However, it is evident that the model did not generate the complete text and clearly did not produce cursive writing.
Finally, a page illustrating the lightning-fast five consecutive whip technique:
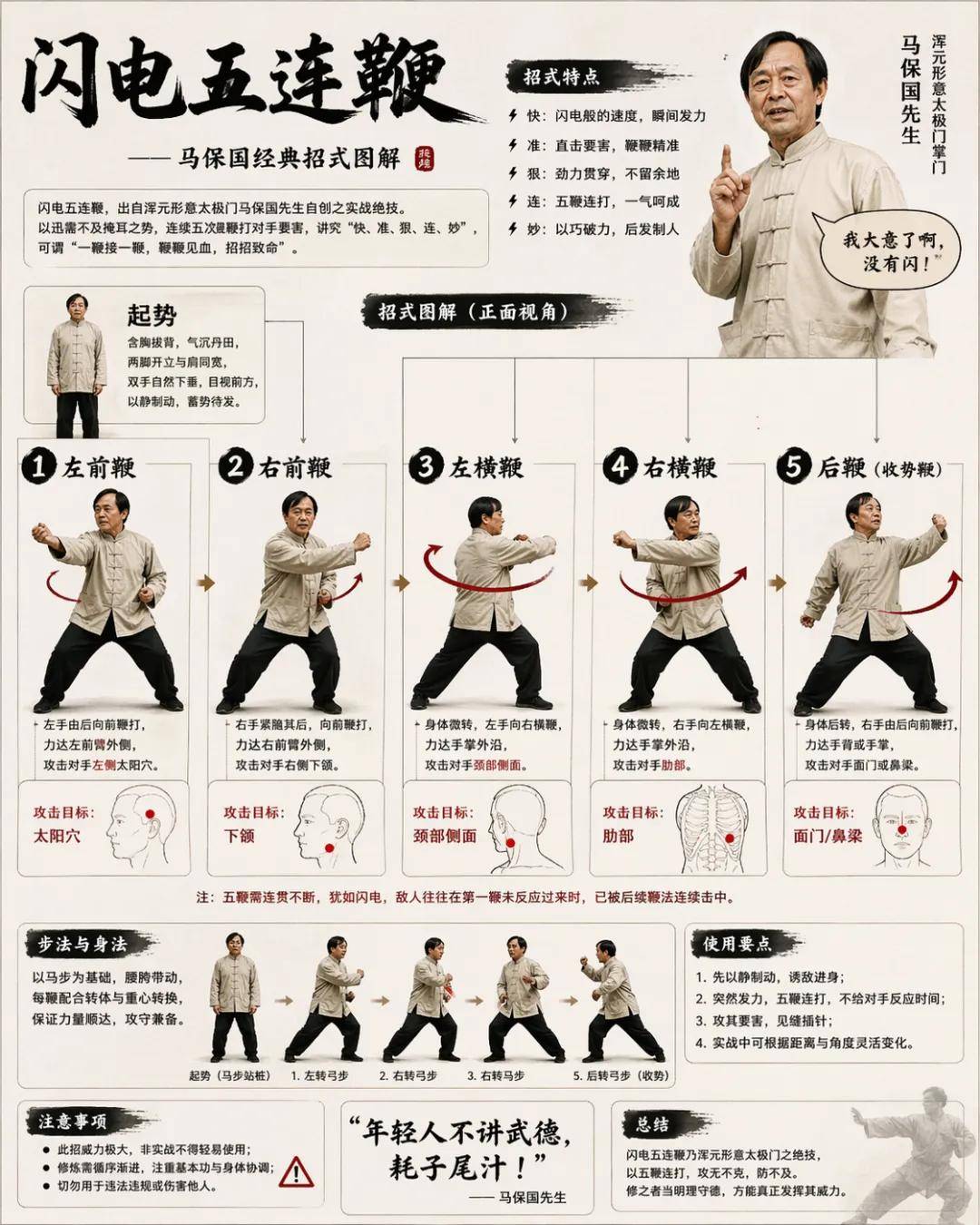
It was quite interesting.
Overall, we feel that ChatGPT Images 2.0 is indeed much more powerful than the current Nano Banana 2; let’s see how Google responds next.
Have you tried ChatGPT Images 2.0? What do you think?
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.